| ������|�й��������̨|��վ��ͼ |
| �ͷ���Ϊ��ҳ |


��̸ | ֱ�� | �㳡 | ����ǽ | ���а�
• ���Ӵ��������ʶ�� • ���ؼ�ʮ����ȫ����
������Ŀ|
̽��������|
�ټҽ�̳|
������Ȼ|
����|
���
ԭ�����|��������|�����й�|��Ȼ����
��ѧ���磨��ͣ����| �ٿ�̽�أ���ͣ����| ���´��| �Ƽ�����
�߱��й�| �߽���ѧ| ��ɫ�ռ�| �Ƽ�֮��
�Ƽ�����| ��������| �л�����| ����
��֤������| ��֤��Ӱ��־| �ط�| ��֤������֮��
������| ������̸¼| ˿·����| �����DZ���
��������| �����ձ�| ��������| �����л���
�����й�| ����| ����֮��ɫ����| ��ת����
ֲ��|����|��ս|����|����|����|ʷ˵����|���ĵ���|�ܵ�|ʱ��|����̽��|�й��ʵ�|���պ���|��Ȥ|��ÿƼ�|�峯|��ʷʱ��|������|UFO|�Ļ�����|��¥��|����|����|�ղ�|��������|Ů��Ů��|Ů��|�Ƶ�|����|�˶�|��Դ����|����|��������|����|��������|����|��ʷ����|�ڽ�|����̽��|����|ר��|����|��ѧ̽��|�������|δ��֮��|����|����|����|���Ҵ�ʦ|����Ѱ��|��������|ս��|��Ȼ����|��ѧ|��������|�¼�|��������|�����¼|�ż���ַ
| �ײ� |
|
|
| �ز� |
|
|
����9 �� 27 �չȸ��Ƴ��¿�doodle����ף�Լ� 13 �����ա�����������ϣ��ȸ輸�����˲����ˡ�����Ϊ��֪���ǣ���13��ǰ������ ����( Larry Page )��л���� ����( Sergey Brin )���������Ƚ����㷨���Ҳ������ȸ�ġ�����������������ɺʹ��¹�˾��������������������ɽ������������ѧ���°ɡ�
 ��ҳ�����ȸ��㷨�ĵ���
��ҳ�����ȸ��㷨�ĵ���
����һ���������������棬����Ĺ�����Ȼ����ҳ���������������Ӧ���������������أ�ʵ���ϣ��ڹȸ���������������֮ǰ������Ϊ�����Խ
������ʱ������Ϊ��ͨ���ж��ܹ���֪�ĸ���ҳ����Ҫ������������ķ�չʮ���а�����������Ȼ����������Ӧ�ð���Ҫ����ҳ�ŵ���������бȽϿ�ǰ�ĵط���
����������⿴���������ף����ǽ���ķ���ȴû���������ô��
�����ڹȸ赮��֮ǰ�Ƕ�ʱ�䣬���е���ҳ�����㷨�������ƣ����Ƕ�ʹ����һ���dz���˼�룺Խ����Ҫ����ҳ���������ͻ�Խ�������˾��ͨ��ͳ����ҳ�ķ�������������ҳ�������������������㷨�����������������⣺һ����Ϊֻ�ܹ�����ͳ�ƣ�����ͳ�����ݲ�һ��ȷ�����ҷ������IJ�����Ƚϴ���Ҫ�õ�ȷ��ͳ����Ҫ������ʱ�����������ֻ��ά�̵ֺܶ���Чʱ�䣻���Ƿ���������һ����������ҳ�ġ���Ҫ�̶ȡ���������һЩ�Ƚ���Ӵ������������ǵã���ʱ�кܶ����Ƴ���ר�š�ˢ���������ķ�����û�и��õķ�������ͳ�Ʒ��������ܹ�Ϊ��ҳ����Ҫ�������أ�
�������������������,1996 ������ȸ蹫˾�Ĵ�ʼ�ˣ���ʱ��������˹̹����ѧ�о���������Ͳ��ֿ�ʼ�˶���ҳ����������о�����1999�꣬һƪ������Ϊ��һ���ߵ����ķ����ˣ������н�����һ�ֽ��� PageRank ���㷨�������㷨����Ҫ˼���ǣ�Խ����Ҫ������ҳ��ҳ���ϵ���������ҲԽ�ߣ�ͬʱԽ���ױ���������Ҫ������ҳ���ӡ����ǣ��㷨��ȫ������ҳ֮�以�����ӵĹ�ϵ��������ҳ����Ҫ�̶ȣ�����ҳ���ױ��һ����ѧ���⣬���ڰ����˷�����ͳ�ƵĿ��
�������Ӻ��㶹��Ϸ��������ϸ��������㷨֮ǰ��������������һ����Ϸ��������ģ��һ�� PageRank �㷨�����й��̣��Ա���߸��õ����⡣
�������ֵܷ� 30 ���㶹�����ÿ�� 10 �ţ�����ÿ�ζ�Ҫ��������㶹ȫ��ƽ���ָ��Լ�ϲ�����ˡ���ͼ��ʾ�����ֵܸ���ӵ�еij�ʼ�㶹�������Լ��ϲ���Ĺ�ϵ����ͷ�����ʾϲ���������϶�ϲ���ϴ��ϴ�ϲ���϶�����������
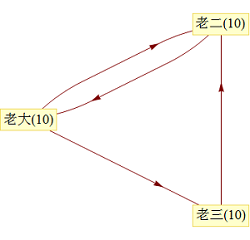
��һ�η�������ǻ�õ�������£�
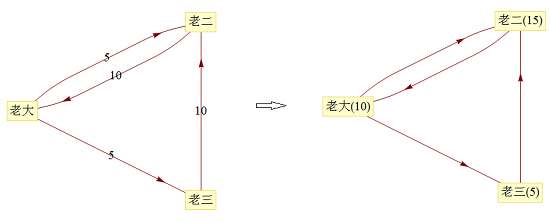
������������Ϸһֱ������ȥ��ֱ���������е��㶹�����ٱ仯Ϊֹ��
������ô�����Ϸ�����Ƿ���Խ����أ�������ԣ����յĽ������ʲô���ģ��ڴ������õ���ģ����������̣��ó��Ľ���ǣ��ϴ���϶������������ 12 ���㶹������������������ 6 ���㶹����ʱ��������Ϸ��ô������ȥ����������㶹�����������ٱ仯��
��������������߿��ܻ��ʣ������Ϸ����ҳ������ʲô��ϵ��ʵ���ϣ� PageRank ���ÿ����ҳһ����ֵ�������ֵԽ�ߣ���˵�������ҳԽ����Ҫ�������ոյ���Ϸ�У�������㶹���������������ֵ�����Բ������������Ѻ����ǿ�����ҳ����ô��Ϸ�Ĺ��̾��� PageRank ���㷨������Ϸ����ʱ�㶹�ķ��䣬������ҳ�� PageRank ֵ��
PageRank����ѧģ��������ͬ��֮ǰ�ķ�����ͳ�ƣ�PageRank ���������һ�����⣺һ�����������������ҳ��ÿ����һ����ҳ֮��ͻ���������ҳ�ϵ����ӷ����µ���ҳ�������ǰ������������ҳ x �Ѿ�ȷ������ô��ҳ x ��ÿ�����ӱ�����ĸ���Ҳ��ȷ���ģ����������� Nx ��ʾ�������������£�����˵������������Ӻ�ǡ��ͣ����ÿ����ҳ�ϵĸ��ʷֱ��Ƕ��٣�
���������ģ���У����������� Ri ����ʾ����� i ������֮�����ͣ����ÿ����ҳ�ϵĸ��ʣ� R 0 ��Ϊһ��ʼ�ʹ���ÿ����ҳ�ĸ��ʣ��������ǽ�֤�� R 0 ��ȡֵ�����ս��û��Ӱ�죩������Ȼ R i �� L1 ��ʽΪ 1 ����Ҳ�� PageRank �㷨������Ҫ��
���������������ϷΪ��������������̵�һ��ʼ�������У�
�������У� A ��ʾÿһ�ε�����Ӹ��ʵľ��� A �ĵ� i �е� j �� A i, j �ĺ����ǣ������ǰ���ʵ���ҳ����ҳi����ô��һ�ε��������ת����ҳ j �ĸ���Ϊ A i, j ��
����������ƾ��� A �ĺô��ǣ�ͨ������ A ������ R n-1 ��ˣ����ɵó����һ�����Ӻ�ÿ����ҳ���ܵ�ͣ���������� R n �����磬�� R 1��= A R 0 �����Եõ����һ�����Ӻ�ͣ����ÿ����ҳ�ĸ��ʣ�
����֮��һֱ������ȥ���У�
����������������ӣ������������ͼ��
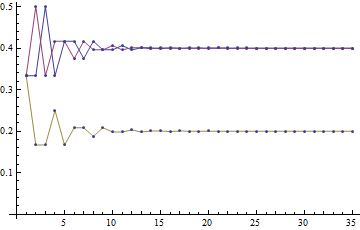
���Կ�����ÿ����ҳͣ���ĸ�������֮�������ȶ���
�����������ȶ�״̬�£����ǿ���֪����������ε��������� R n = R n-1 ���������Ǿͻ����һ�����̣�
���������������Ĺ��̣�������Ѱ�� R = AR �Ľ⡣������ R 0 �Ƕ��٣����������֮��һ����ȡ���� R = AR ������ R ֵ��������� R �Ĺ��̣�����ͬһ������һ�ŵ�ͼ�ϵIJ�ͬλ��֮�����������һ�������Ա���Ϊ���������ģ�͡���
�����������ģ����һ���������ص㣬�Ǿ���ÿһ�ε����Ľ��ֻ��ǰһ���йأ������Ľ����ȫ�ء����ֹ����ֱ���Ϊ�����ɷ���̣� Markov Process ���������ɷ����� Markov Chain ����
���������ɷ���̵���ѧ�����ǣ��������һ������������� X 0 �� X 1 �� X 2 ������ ���� X n ��ʾʱ�� n ��״̬��ת�Ƹ���P���У�
������ X n ֻ�� X n-1 ��Ӱ�죬��˹��̳�Ϊ�����ɷ���̡����� P( X n+1 | X n ) ������һ��ת�Ƹ��ʡ���������������ת�Ƹ��������ͨ��һ��ת�Ƹ��ʵĻ�����á�
������״̬�ռ�����ʱ��ת�Ƹ��ʿ�������һ������ A ����ʾ������ת�ƾ��� transition matrix ������ʱת�Ƹ��ʵĻ��ּ�Ϊ������ݣ�k��ת�Ƹ��ʿ����� A k ��ʾ����Ҳ���������ģ���е������������һ�����ģ�ÿ��Ԫ�ض�Ϊ���ģ�ת�ƾ��� A ������֤��һ���У�
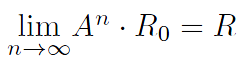
�������������Ϊʲô R 0 ��ȡֵ�����ս��û��Ӱ�졣
������������ҳ�������IJ���Ӱ����������������һ�����⣺���� R 0 ��ȡֵ�����ս��û��Ӱ�죬�� R ��Ϊ��ҳ����������Ƿ���ĺ�����
������ʵ������������Ϊ��һ����ҳֻ����������û���������ӵ�ʱ�������ҳ�ͻ���һ�����ڶ���һ������ͬһ����ͨ��ͼ��������ҳ�������� PageRank �������̵�������Ϊ�㷨��������û�һ��������������ҳ�� �ͻ�����û�ж������Ӷ���Զͣ���������������ҳ���dz�֮Ϊ��������ҳ���� Dangling Link �������֡��ڶ���ЧӦ����������� ��������һ����ͨ�����õĻ������ϣ� ����ֻ��һ�� ��������ҳ���� Ҳ����ʹ��������������ҳ����ʧЧ�� ��ν�� ��һ������ʺ����һ���ࡱ��
����Ϊ�˽��������⣬����Ͳ��ֽ�����������������ʶ���� ���û����ʵ� ��������ҳ�� ʱ�� ��������Ҳ��Ӧ�þ�ͣ���������ҳ�棬 ���ǻ����з���������ҳ����Ȼ��ÿ���û���˵�� ���з��ʵ���ҳ����˵���Ȥ�йأ�����ƽ������������������Ͳ��ּٶ��û����������������������ѡȡһ����ҳ���з��ʡ�
�����������Ǹ� PageRank �㷨������һ���µ����� E�����������ǣ����������������ı�������ȫ����ҳ����������ҳÿһ�Ρ��̵����� PageRank���������൱��Ϊ������ҳ����������������ȫ����ҳ�����ӣ��������������ӵij��֡�
�������Ͼ��ǹȸ豳������Ҫ����ѧ���ء� ����������ƾ��ؼ��ʳ��ִ�������������ͬ�� ������������ҳ���������ȷ���������Dz���ô�������ٵģ� ��Ϊ���������ǰ��Լ�����ҳ�����컨���� ���û�����������˵����ݣ� ���˲��������� һ�оͻ�����Ȼ�� ���� ���������� ����һ����Ҫ�ص㣬 �Ǿ�����ֻ�뻥�����Ľṹ�йأ� �����û����������Ķ����ء� ����ζ�����������Ե������У� ���������û���������ָ������ʱ���С� �ȸ��������ٶ�֮���Կ�ݣ� �ںܴ�̶��ϵ����ڴˡ�
������������Ҫǿ�����ǣ���ȻPageRank��Google��������������Ҫ���ݲ��Դ˷��ң�������������ȫ�����ݡ���ʵ���ϣ�Google��չ�����ڣ���ͬʱ���������ֲ�ͬ���㷨��ȷ��������ʾ���û����������˳��
��������PageRank����һ��С���¡����� ������Google�Ĵ�ʼ��֮һ��Ҳ������Google��CEO������˼���ǣ������桱��Ӣ���ǡ�Page����ǡ���롰PageRank���ġ�Page�����Ǻϡ������ɺϻ�������Ϊ֮�أ��������ϱ��߿����ҵ������������У����ᵽPageRank�������� �����������������������Щ���϶�û���ᵽ������Ϣ����Դ����������ʵ���ӵ�֤��
������������Ȼ���汾��û�г������ͣ�������Ҳû�б�Ҫ������Page�ĺ����ˡ���������ʱ���������������˫���������ǿ���һ��С��Ц�أ�
�����ο����ϣ�
����[1] ¬������ �ȸ豳�����ѧ
����[2] L. Page, S. Brin, R. Motwani and T. Winograd. The PageRank Citation Ranking: Bring Order to the Web. Jan, 1998.
����[3] ά���ٿƣ� �����ɷ����
�ȴʣ�
����㲥������̨ �й��������̨ ��Ȩ����
Υ���Ͳ�����Ϣ�ٱ� ��ICP֤060535�� �����ġ�2014��0383-083��
���ϴ���������Ŀ����֤�� 0102004 �³���֤��������098�� �й�������������Ŀ�������ɹ�Լ























